- Bezprawnik -
- Praca -
- CriticGPT może być początkiem końca rynku programisty. OpenAI zaprezentowało nowe narzędzie AI
CriticGPT może być początkiem końca rynku programisty. OpenAI zaprezentowało nowe narzędzie AI
W czwartek OpenAI zaprezentowało światu CriticGPT – nowe narzędzie AI zaprojektowane na podstawie modelu GPT-4. Jego zadaniem jest wykrywanie i identyfikowanie błędów w kodach generowanych przez ChatGPT, który nieprzypadkowo również jest zasilany modelem GPT-4.


W artykule naukowym LLM Critics Help Catch LLM Bugs (LLM – Large Language Model, czyli model sztucznej inteligencji odpowiedzialny za generowanie treści dzięki przetwarzaniu języka naturalnego; przykładem LLM jest GPT-4) naukowcy OpenAI opisują działanie ich nowego narzędzia. Proces uczenia CriticGPT zaczął się od dostarczenia danych (zapytanie + odpowiedź), które celowo zawierały błędne odpowiedzi. Miało to spowodować lepszą precyzję w stwierdzeniu obecności oraz identyfikacji typu błędu. Ma to oczywiście swój powód, ponieważ kolejnym krokiem było wykorzystanie opinii ludzkiej nt. poszczególnych odpowiedzi stworzonych przez model – trenerzy AI mogli w ten sposób porównać wygenerowaną odpowiedź wraz z zawierającą celowy błąd, którą wcześniej sami umieścili. Wykorzystana metoda nazywa się Reinforcement Learning from Human Feedback, jest jedną z technik uczenia maszynowego, która spośród innych wyróżnia się m. in. wykorzystaniem ludzkiej informacji zwrotnej.
OpenAI: werdykty wydawane przez CriticGPT nie zawsze są poprawne
Twórcy mówią o tym otwarcie, jednocześnie przyznając, że wyrażane sugestie mogą niewątpliwie pomóc w wychwytywaniu błędów w odpowiedziach napisanych przez ChatGPT – szczególnie w czasach, gdy modele AI stają się coraz bardziej zaawansowane, a popełniane przez nie błędy coraz bardziej subtelne. Badania wykazały, że w 60% przypadków osoby korzystające z CriticGPT radziły sobie lepiej niż te, które z niego nie korzystały. Eksploatacja nowego dziecka OpenAI ma jak najbardziej sens – nic dziwnego, że sami twórcy planują jego dalszy rozwój. W artykule naukowym sami przyznali, że LLMy swoją wszechstronnością i skomplikowaniem już przekroczyły punkt, w którym człowiek może oceniać wyniki ich działania bez jakiejkolwiek pomocy.
Jedną z istotnych wad generatywnych modeli sztucznej inteligencji jest tzw. „halucynacja”. Jest to zachowanie polegające na dostarczeniu przez AI niedokładnej lub zupełnie błędnej informacji – dzieje się to np. w sytuacji, gdy AI jest niepewna swojej odpowiedzi i zaczyna ją częściowo lub całkowicie zmyślać, jednocześnie starając się zachować pozory tego, że coś takiego nie miało w ogóle miejsca. Raz może wyglądać to wręcz komicznie, bo dowiadujemy się rzeczy kompletnie nielogicznych i sprzecznych z naszym stanem wiedzy, ale innym razem możemy tego nawet nie dostrzec.
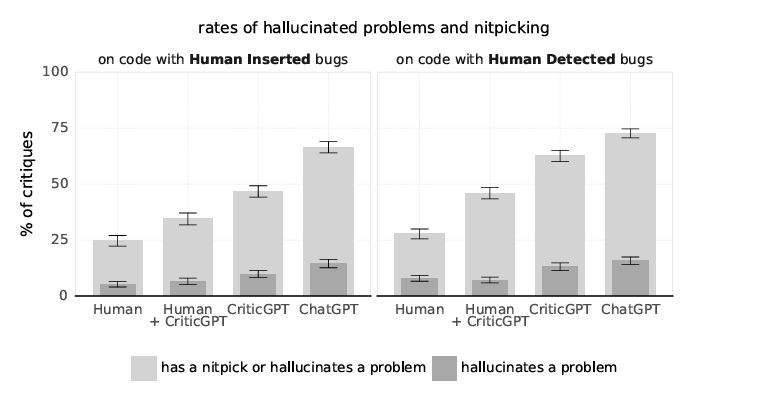
Źródło: LLM Critics Help Catch LLM Bugs, OpenAI
Okazuje się, że przy wykorzystaniu CriticGPT zjawisko halucynacji występuje rzadziej niż w przypadku ChatuGPT, który jako generatywny model sztucznej inteligencji również w pewnym stopniu posiada zdolność do rozpoznawania błędów w odpowiedziach – stąd to porównanie. Bez zaskoczenia dowiadujemy się także o wyjątkowej efektywności połączenia pracy człowieka wraz z pracą CriticGPT – daje to znacznie lepsze osiągi niż wyłączne poleganie na pracy sztucznej inteligencji.
CriticGPT z racji bycia produktem młodym i będącym nadal we wczesnej fazie rozwoju jest w wielu kwestiach ograniczony. Nie jest przystosowany do pracy z najbardziej skomplikowanymi i zawiłymi problemami związanymi z rozwojem oprogramowania. Twórcy przyznają, że nowy model koncentruje się jedynie na rozpoznawaniu błędów kodu skupionych w jednym miejscu – umiejętność identyfikowania błędów rozproszonych to dopiero przyszłość.
Najpierw programiści, a później reszta?
CriticGPT nie bez powodu skupia się w pierwszej kolejności na rozpoznawaniu błędów programistycznych. Badacze stwierdzają, że pisanie kodu jest głównym zastosowaniem dzisiejszych LLM, dlatego sprawienie, aby modele sztucznej inteligencji dawały nam lepszy kod, miałoby praktyczną wartość – błędny kod wpływa negatywnie na pracę systemów informatycznych wykorzystywanych w poszczególnych dziedzinach życia.
Nowy model OpenAI jest niewątpliwie nastawiony na usprawnienie i zautomatyzowanie pracy programistów – zarówno zwykłych „klepaczy” kodu, jak i samych specjalistów zajmujących się trenowaniem najbardziej zaawansowanych modeli sztucznej inteligencji. Póki co, CriticGPT nie jest na tyle rozwinięty, aby zrewolucjonizować pracę programistów od zaraz, ale jego obecność z pewnością wykonuje krok w tym kierunku. W najbliższych latach możemy być świadkami zdefiniowania zawodu programisty na nowo - może stać się on raczej osobą nadzorującą sztuczną inteligencję piszącą kod, a nie byciem osobą piszącą kod.
Język naturalny to język programowania przyszłości
Słowa Jensena Huanga dyrektora generalnego Nvidii, która kontroluje 80% rynku sprzętu eksploatującego systemy sztucznej inteligencji, zdają się w pewien sposób to potwierdzać:
Uczynienie języka ludzkiego językiem programowania będzie możliwe dzięki coraz bardziej zaawansowanym systemom przetwarzania języka naturalnego (natural language processing, NLP). Rozwój NLP to przenikanie sztucznej inteligencji w kolejne dziedziny życia w coraz bardziej profesjonalny, mniej awaryjny oraz bardziej przystępny sposób. Tłumaczenie języków obcych, interpretacja aktów prawnych, tworzenie treści multimedialnych – nie są to rzeczy obce dla sztucznej inteligencji. Oczywiście wiele rzeczy jest jeszcze do udoskonalenia, ale niewątpliwie czeka nas dalsza automatyzacja i sprowadzenie nas do roli nadzorcy sztucznej inteligencji, a w niektórych przypadkach nawet do całkowitego zastąpienia - w końcu CriticGPT to tak naprawdę AI nadzorujące inne AI.
zobacz więcej: